
| Version 63 (modified by , 12 years ago) ( diff ) |
|---|
BluePrint: Text Search
Table of Contents
Introduction
Name : Vishrut Mehta
github : https://github.com/VishrutMehta
IRC Handle : vishrut009
Email id: vishrut.mehta009@gmail.com
skype: vishrut009
The Blueprint outlines the development of two functionalities for Sahana Eden. They are:
Full-text Search
- It will provides users to search for text in uploaded documents.
Global Search
(Do this if time permits)
- It will provide users to search for a particular query really quick over multiple resources together(eg. Organization, Hospital, etc.).
(Note: For the GSoC Project, we will try to make the basic structure of the global search and extending its functionality and a nice UI display will be out of the scope of this project. This work can be done as a post GSoC work)
Stakeholders
- The End Users - The group of end users are a heterogeneous mass and would like to search to any type of specific queries.
- Site Administrator, Site Operators,
Agencies like:
- TLDRMP : Timor Leste Disaster Risk Management Portal
- CSN : Community Stakeholder Network
- LAC: Los Angeles County
- IFRC : International Federation of Red Cross and Red Crescent Societies
Use Cases and User Stories
For Full-Text Search:
For Unrelated Search
- As a user, I want -
To be able to search through contents into ALL the documents as a user I may not know the resource or relevant module to search into.
- As a developer or an admin, I want -
expand and would like to test my search results and increase the efficiency of the search result.
For Related Search
- As a user, I want -
To be able to search through contents of the uploaded document into relevant resource as I would be somewhat familiar with the system and would know where to search for what.
- Many agencies would like to have there search method efficient. So as Eden does not have a search functionality to search Into the documents, by this project we would try to implement this, so for users convenience and efficiency of the search, we would add this functionality.
- As a developer, I would like to -
expand the current functionality and increase the efficiency of the search results.
For Global Search:
- The user will type the query of the upper right corner of the the page, where the global search option will be there. So as a User -
I may want quick and rough results of every records of all resource, rather going to a particular resource and try to search in that. This will provide the user rough set of search list to the user of the different resources. This is a User Convenience to have a single search box which searches globally across the site. As Fran told me, this concept comes from websites rather than applications, but users expect this kind of convenience.
- As an agency,
The current IFRC template design has this functionality, so as a part of this project, I will try to accomplish this, but will be a lower priority than the document search
- The users may want to enter context hints in the global search and would like to search for it. For eg. If I enter "staff" into the search box, then I want to get a list of staff - or at least a list of links to the pages relevant for "staff". (beyond the scope of GSoC)
Use Case Analysis
Target Problem
The Full-Text Search will try to solve two problem:
- To find one particular item(document/record).
- To find all items Relevant for a task the user is to perform.
The Global Search will solve the following problem:
- To search for a particular item through all the Resources.
- The Use Case for this is the IFRC UX design contains the global search query box, so we would add this functionality to these type of agencies.
The use cases for Global Search as discussed in the mailing lists are:
Benefit to Sahana Eden
- A new functionality for searching text into the documents will be implemented as a part of this project. Till now no such system exits. So when the user wants to search for a particular document/report, relevant text search should be able to give efficient search results.
- For IFRC, the UX design contains a Global Search option on its upper right corner. This will not be an urgent priority(could be done in the third trimester).
Requirements
Functional
For Full Text Search:
- Proper understanding and the work model of S3Filter is required.
- Literature study of Apache Solr and Pylucene. Getting familiar with both of the and deploy it into my local machine.
- Studying the linkage of the Lucene daemon and web2py server.
- Extend the functionality of S3Filter by introducing an addition feature (which is a text field) to search for text through documents.
- A user interface for displaying the search result.
For Global Search
- Appropriate understanding for the S3Filter, and we would use S3TextFilter after configuring the context links, so need to learn that also..
- Need to search for a particular resource over all the resources.
- Efficient search mechanism to search over all the resource.
System Constraints
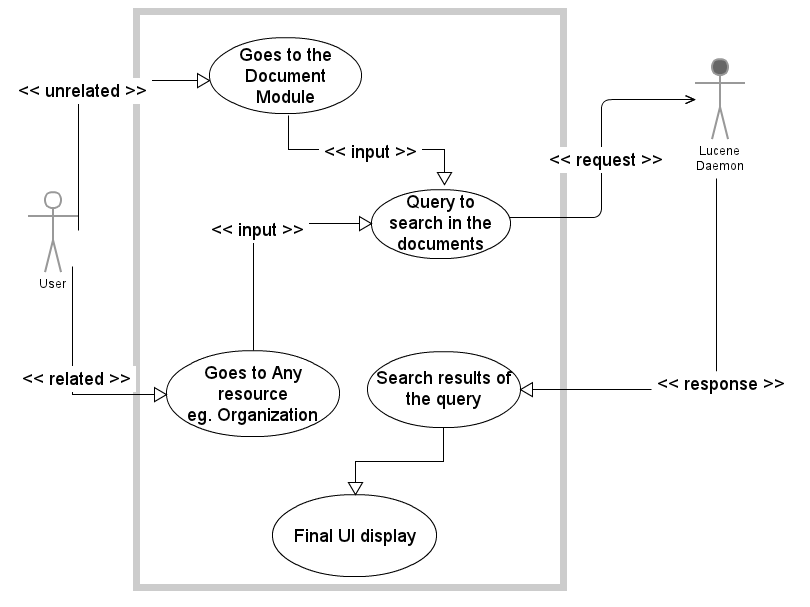
Use-Case Diagram

Design
Workflows
For Full-Text Search:
- The workflow will be according to the use case described above. First the user should need to analyze whether he wants to search through all the uploaded documents or any resource specific document.
Unrelated Search:
- The user should go the the Document -> Search.
- For Simple Search: Tick the checkbox to search through uploaded documents.
- For Advanced Search: Type the following query(string) he wants to search for.
- The output will be the response of the Lucene Daemon running in the background.
- The response will be displayed in the form as the search result for that query.
Related Search:
- This type of search is to search for text in uploaded documents over multiple resources.
- Go to that particular resource(eg. Hospital, Organization, etc) -> Search.
- You have to type the particular resource in which you want to search(normal search) and also string in the text filter for document search.
- For Simple Search: Tick the checkbox to search through uploaded documents in related resources.
- For Advanced Search: It will search on the basis of the resource associated to the document and the search string for the document search.(So we will limit our search to only those documents for which a particular resource is associated.)
- The response will be recorded and displayed as an output. Here there will be two categories of output. The first one would be the normal output of the search filter form and after that we would show the search results for the output of the full-text based query (the display/UI would be same as for unrelated search).
For Global Search:
- The user want to search through all the resource, then he will go to the global search option on the upper right corner of IFRC template.
- The user need to type the resource or text he wants to search for.
- The back-end processing happens and efficiently filters the resources and displays the output.
- The main task on how to categorize the output. We will divide the output form into category of resources in alphabetical order. For eg. Assets, CAP, GIS, Hospitals, etc.. So the category heading would be this resource and the output will be the corresponding records which match the search request.
Site Map
Wireframes
todo
Technologies
The technology going to be used are:
- S3Filter, S3TextFilter, S3Resource and S3ResourceFilter
The resource for these are here:
http://eden.sahanafoundation.org/wiki/S3/FilterForms
- Pylucene or Apache Solr
A comparison analysis was done here whether to choose between Apache Lucene or Apache Solr.
http://www.alliancetek.com/Blog/post/2011/09/22/Solr-Vs-Lucene-e28093-Which-Full-Text-Search-Solution-Should-You-Use.aspx
Solr is a platform that uses the Lucene library, the only time it may be preferable to use Lucene is if you want to embed search functionality into your own application. So I choose Lucene for indexing the documents and search string in those documents.
Apache Lucene is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
Refer this for more information about its functtionalities:
http://lucene.apache.org/core/
Planned Implementation
Full-Text Search
- As suggested by Dominic, First, we need to send the uploaded documents to the indexer(to a external content search engine like Solr/Pylucene) in onaccept.
- We need to make a Filter Widget for upload files which would be a simple text field for Advanced search and checkbox for simple search.
- We need to extend the functionality of the S3ResourceFilter after extracting all result IDs in S3Resource.select .
- Then after extracting all the id's, it would identify all the document content filters, then will extract the file system path and then run them through the external contents search engine (Apache Solr/Pylucene), which would in turn return the IDs of the matching items along with the documents.
- Along with the IDs, we also need the snippet of the matching text in the respective document (as there in Google Search)
- After running the master query against the record IDs which we obtained from filtering, we combine the results and show up it in the UI.
- We also need to have a user friendly UI for the users(take inspiration from the Google or Bing! search results.)
- The main thing we could focus on is the efficiency of the search, as we know it will be Computationally challenging to perform accurate search.
- After the response, the part which remains will be displaying the search results in a proper user friendly format.
- The UI display for the search record would be something like:
Result:
<file type(in superscript)><The line or title containing the query(string to be searched) text> <Resource>
The path of the file, file name and uploaded date-time
<the snippet of 2-3 lines of that document>
This will be format for the UI display for each matched record.
Future Implementation:
- UI is a secondary concern for how to display the search result. We could take inspiration from the Google and Bing! Search results for an attractive UI format.
Global Search
- At first, we need to index the uploaded document by defining a new onaccept method for this global search.
- We will look a the design implementation of IFRC template, and add the global search text box using S3Filter and S3TextFilter.
- We would need to flatten the records and its components into a text representation.
- After doing this, we need to include the important information of the resource as well as the important information of its component in form of List.
For eg. list(or a dictionary) would be like "Sectors: Food, Something Else, Another Sector" "Type: Organisation, Name: <name of org>"
- After getting this information, this is when Solr will come into play and will do the full-text search on these information. So we wold get the information of the search results doing the REST calls and thus we need to output the search results.
- After doing this and filtering out the common context, we would need a UI to display it. It would be simple, user friendly and categorized. Showing it in a much better way would be for future implementation.
- The UI presentation will be a Categorized display, something like:
Search: DRR
Result:
Sector "DRR":
(Records corresponding to this)
- 5 Projects related to "DRR"
- 7 Programmes related to "DRR"
- 3 Events related to "DRR"
Location "Taiwan DRR Centre":
- 1 Event related to "Taiwan DRR Centre"
- 5 Staff Members related to "Taiwan DRR Centre"
...and so forth.
Testing
This will include two type of tests:
1) Selenium tests for correctness of the code and the Eden framework
2) Unit tests for efficiency test(it will also cover manual tests to check the efficiency of the search results)
References
Mailing List Discussion
https://groups.google.com/forum/?fromgroups=#!topic/sahana-eden/bopw1fX-uW0
Chats and Discussions
http://logs.sahanafoundation.org/sahana-eden/2013-03-24.txt
http://logs.sahanafoundation.org/sahana-eden/2013-03-24.txt
http://logs.sahanafoundation.org/sahana-eden/2013-04-20.txt
Online Resources
http://lucene.apache.org/core/4_2_1/queryparser/org/apache/lucene/queryparser/classic/package-summary.html#Boosting_a_Term
http://lucene.apache.org/pylucene/features.html
http://oak.cs.ucla.edu/cs144/projects/lucene/
Attachments (1)
- search.png (32.4 KB ) - added by 12 years ago.
Download all attachments as: .zip

{kind=link}