
| Version 50 (modified by , 15 years ago) ( diff ) |
|---|
Table of Contents
Blueprint: VITA Person Entity Model
Version 2.0 - under construction
VITA is the proposed application design for storage, manipulation and communication of person-related information in SahanaPy. It defines a set of data structures, interfaces and interoperability features to be implemented.
Overview
VITA defines:
- an extensible data model for tagging, tracking and tracing of person entities
- a set of interfaces to request and manipulate person entity data
- an XML-based data format to communicate person entity data
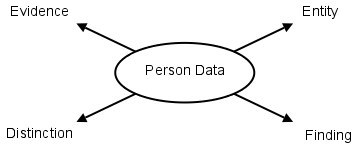
4-Axes-Model
VITA defines four axes (aspects) for the construction of "Personal Data":

- Appearance - the entity type the data set relates to
- Distinction - assigned features for operational distinction
- Finding - features to be communicated by the data set
- Evidence - to describe the quality of the data
Any compliant set of personal data implements at least one feature for each axis.
Appearance
The appearance axis determines the entity type to which the data set relates (=ownership), which can be types of:
- Individual
- Group
- Body
- Personal Effects
- Relationship
The Appearance axis does not describe the actually observed appearance form of a person, which indeed can be multiple at the same time.
Distinction
Distinction is to be understood as any features which are used to distinguish particular entities in operations.
It is important to understand that Distinction features are always assigned, i.e. not naturally given - they cannot be observed but have to be communicated. The most commonly used distinction feature for person entities are names.
Distinction features may be ambiguous, even within the same domain (e.g. database). However, it is desirable to assign at least at least one unique feature in order to identify person entities. Such unique features are called Identity (ID).
Identities don't have to be unique across multiple domains. In case they are not, any communications of identities have to enclose a reference to the domain that originates the identity.
Findings
Findings are all other features of the person entity which are to be communicated in this data set. These features can be assigned, observed or derived.
Evidence
Evidence is a means to describe the quality of findings data. This always includes at least information on origin and time of the particular finding, but can also include references and links to sources, or information on methods of determination. This can even enclose the originating sources themselves, e.g. photograph images.
Ontology
Ontology draft for "Personal Data for Disaster Management":
(still under development, see the OWL source for version information)
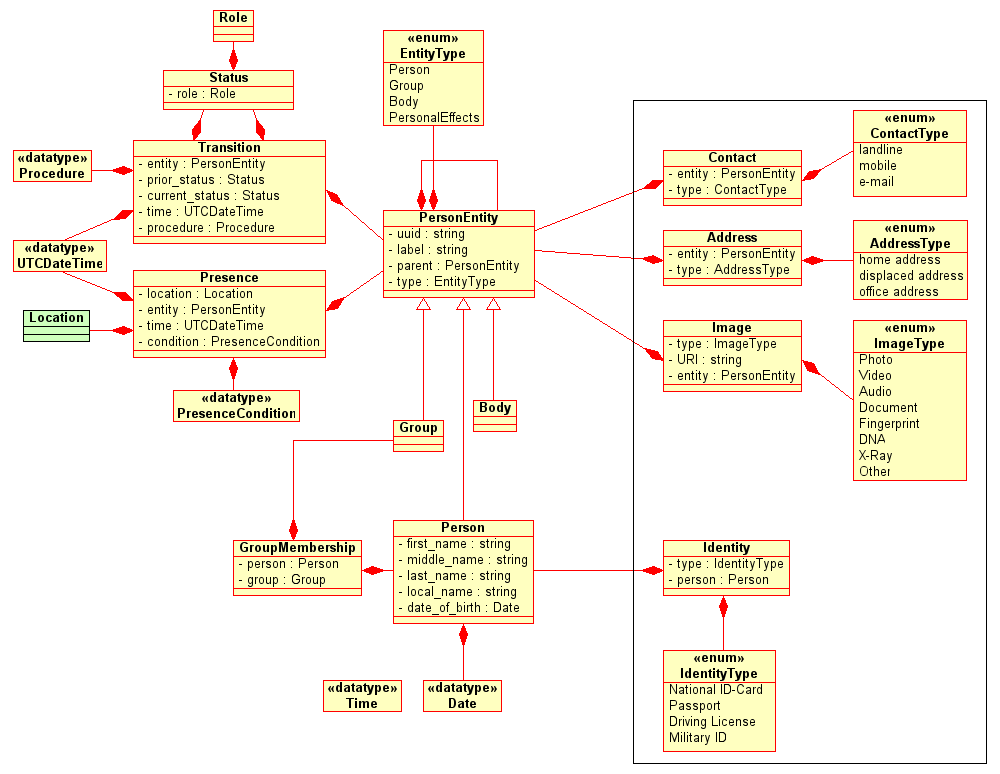
The Data Model
under construction

Presence Log
Presence means the fact, that an entity is physically there at a particular location at a particular time. This abstract construction covers even cases of explicit absence, i.e. when the entity is not present at that location at that time.
VITA applications record a presence log for each person entity. Each log entry is established through a recognition event, i.e. when the entity is recognized by a dedicated observer (human or automatic).
Recognition might happen implicitly, e.g. when other data are obtained directly from the entity. In these cases, the time and location of the observer are used for the record. Recognition can also happen explicitly, i.e. in response to observation requests. In such cases, the observation time and location determined by the request are used.
Locations in presence records represent geospatial features, which can basically be of any valid feature class (points, polygons, lines etc.). Where references to locations are used, they must be universally unique and resolvable; otherwise the referred geospatial information have to be enclosed in the database and/or communication.
In contrast to that, time in this regard means one exact time point, to be stored as coordinated universal time (UTC, Gregorian date including century) with a minimum precision of one second. References or relative times must not be used.
Presence Conditions:
Check-In arriving at this location for storage/accommodation Check-Out released from this location after storage/accommodation Reconfirmation re-confirmation of storage/accommodation at this location (on request) Found only temporarily at this location, accidentally found Procedure temporarily at this location for a procedure Transit temporarily at this location between two transfers (specify origin and destination) Transfer released from this location to be transferred to another (specify destination) Missing no longer present at this location, but missing Lost no longer at this location, but destroyed/disposed/deceased here
Names
Names are used to identify persons in human communication. However, names of persons do not have to be unique nor do they have to be exact, and thus are no reliable identity features. The following name fields are mandatory to exist in person records:
- first_name the first names (or the only name) of the person, in romanized script
- middle_name the person's middle name (if customary), in romanized script
- last_name the last name (mostly the family name) of the person, in romanized script
- local_name the full name of the person, in a local language and script
Conventions:
- Any of these mandatory name fields may be empty in a particular record except first_name.
- A name field value starting with a question mark ? indicates that this part of the name is uncertain or unknown.
- 'first', 'middle' and 'last' refer rather to the usual writing order of a person's full name than to the meaning of the name parts.
- There is no need to split the full name into segments if that is not customary in the person's country of origin - in such case first_name should represent the person's full name.
- In case there are multiple local languages, the local_name should be in the language/script that is most likely readable by that person and/or their relatives.
- An application may define additional name fields to represent e.g. titles, nicknames or pseudonyms, however, these additional fields must not be used to repeat or replace any of the mandatory fields.
Motivation
Rationale
Implementations
- SahanaPy Person Management (in progress)
Attachments (2)
-
vita.png
(66.6 KB
) - added by 16 years ago.
Data Model Overview
- person_data_axes.png (8.3 KB ) - added by 15 years ago.
Download all attachments as: .zip

{kind=link}
{kind=link}
{kind=link}