
S3Hierarchy
Table of Contents
Purpose
The S3Hierarchy toolkit can be used to perform lookups in hierarchical taxonomies. It analyses the parent-relationships of the records, and provides methods to access and search through the parent-, child- and sibling-axes of each record.
Example
Facility type as an example for a hierarchical taxonomy:
- Arts and Recreation
- Recreation Centers
- Community Groups
- Volunteer Opportunities
- Education
- Adult Education
- Guidance and Tutoring Programs
- Health and Mental Health
- Dental Care
- Health Centers
- Health Clinics
- Health Screening and Testing
- Hospitals and Medical Centers
- Mental Health Counseling
- Mental Health Programs
- Public Health Programs
- Substance Abuse Programs
- Social Services
- Children and Family Services
- Public Information Services
- Senior Services
- Support Groups
Data Model
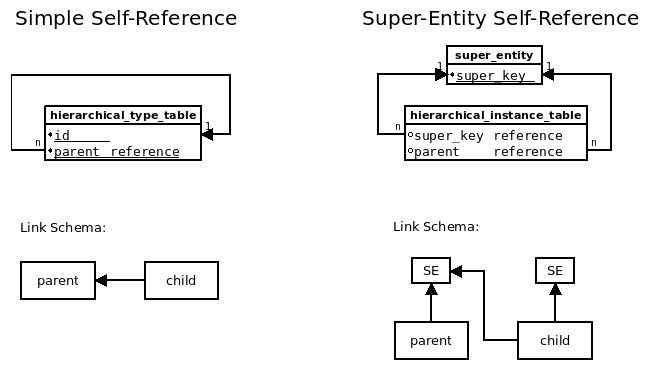
To store a hierarchical taxonomy, the database table must include a parent reference (self-reference). This can either be a foreign key to the table, or - if the table is a super-entity instance - a (second) reference to the super-entity.
The diagrams explain the two models:

A typical data model for a hierarchical taxonomy (with simple self-reference) could look like:
tablename = "org_facility_type"
define_table(tablename,
Field("name",
),
# The parent-field for the hierarchy:
Field("parent", "reference org_facility_type",
),
s3_comments(),
*s3_meta_fields())
configure(tablename, hierarchy = "parent")
For a super-entity self-reference, the parent-field is defined as reference to the super entity:
tablename = "vulnerability_indicator"
define_table(tablename,
# Instance table of stats_parameter
super_link("parameter_id", "stats_parameter"),
# The parent-field for the hierarchy:
Field("parent", "reference stats_parameter",
),
Field("name",
),
s3_comments(),
*s3_meta_fields())
configure(tablename, hierarchy = "parent")
Configuration
The hierarchy is configured in the model as the field name of the parent reference:
self.configure(tablename, hierarchy="parent")
If categories (e.g. level) are to be used, the hierarchy is configured as tuple of parent reference and category field:
self.configure(tablename, hierarchy=("parent", "level"))
Subset Definition
A subset is an S3Hierarchy instance. With the tablename as only parameter for the constructor, the subset would include all records in the hierarchical table (...which are accessible for the user):
subset = S3Hierarchy("hierarchical_type_table")
To filter the records, a filter query can be specified as keyword parameter:
query = (FS("filter_field") == 5)
subset = S3Hierarchy("hierarchical_type_table", filter=query)
Note that the hierarchy is only loaded from the database when a lookup is performed (lazy instantiation). Also, the hierarchy will not be loaded again until the end of the request (unless it is marked as "dirty" during the request) - regardless how many subsets are created or lookups performed.
Performing Lookups
To perform lookups, you first have to define a subset.
All lookup attributes or methods of the subset use node IDs. The node IDs are either the record IDs (for simple self-reference) or the super-IDs (for super-entity self-reference) of the records in the subset.
All lookup attributes and methods return either a single node ID (long), or a set of node IDs. The only exception is path() which returns an ordered list of node IDs.
Root Nodes
To get all root nodes of the subset, use:
# Returns a set of node IDs root_nodes = subset.roots
To get the root node for a particular node, use:
# Returns the root node ID for node_id (or node_id if it is a root node itself) root = subset.root(node_id)
Child Nodes
To get all child nodes of a node, use:
# Returns the first generation of child nodes for node_id children = subset.children(node_id)
To get all descendants of a node, use:
# Returns all descendant nodes (any generation) for node_id children = subset.findall(node_id)
It is possible to use findall to get a union set of descendants for multiple parent nodes:
# Returns all descendants in all specified nodes children = subset.findall((node_id_1, node_id_2, node_id_3))
Parent Nodes
To get the parent node ID for a node, use:
# Returns the parent node ID for node_id (or None if node_id is a root node) parent = subset.parent(node_id)
Sibling Nodes
To get all sibling node IDs for a node, use:
# Returns all sibling node IDs for node_id siblings = subset.siblings(node_id)
This does not normally return node_id itself, unless you specify inclusive=True:
# Returns all sibling node IDs for node_id - including node_id itself siblings = subset.siblings(node_id, inclusive=True)
Path
The path of a node is an ordered list of all generations of parent node IDs from the root node down to the node itself. It can be requested by:
# Returns the path of a node (root node first) as ordered list path = subset.path(node_id)
Using Categories
Categories can be used to classify nodes "horizontally", e.g. to indicate a hierarchy "level". To use them with the hierarchy toolkit, an additional category-field must be defined in the hierarchy configuration:
self.configure(tablename, hierarchy=(parent_field, category_field))
Categories are neither managed nor inferred by the hierarchy toolkit, but they can be used to filter the lookup axis.
Filtering the Lookup Axis
This is useful e.g. to find all descendants of a node of a specific category:
# Define a hierarchy of locations with "parent" as parent-reference and "level" as category
subset = S3Hierarchy("gis_location", hierarchy=("parent", "level"))
# Lookup all descendants of location #3 with category "L3"
communes = subset.findall(3, category="L3", inclusive=True)
When performing a root lookup, we may be interested in the closest parent of a particular category rather than the absolute root:
# Lookup the closest "L1" parent of location #454 state = subset.root(454, category="L1")
This does also work with path lookups:
# Lookup the path of location #378 down from the closest "L1" parent path = subset.path(378, category="L1")
The category parameter can be used analogously with the children() and siblings() methods.
Looking up the Category of a Node
To lookup the category of a node, use:
# Returns the category for node_id (e.g. "L1") category = subset.category(node_id)
To get the category of each node in the result of the parent(), root(), path(), children(), findall(), or siblings() methods, use the classify-flag like:
# Returns the children of location #328 as set of tuples like: set([(367, "L3"), (368, "L3")]) children = subset.children(328, classify=True)
S3HierarchyWidget
The S3HierarchyWidget can be used as hierarchical selector in CRUD and filter forms.
Hierarchical Query Operator typeof
The typeof query operator can be used to filter by a type and all its sub-types in a hierarchical taxonomy.
It can be used with a reference (or list:reference) to a hierarchical table:
query = FS("site_facility_type.facility_type_id").typeof(4L)
or with a field within the hierarchical table:
query = FS("site_facility_type.facility_type_id.name").typeof("Hospital")
For string fields within the hierarchical table, "*" can be used as wildcard:
# Matches e.g. "Fuel Depot", "Goods Depot" etc, and all their subtypes
query = FS("site_facility_type.facility_type_id.name").typeof("*Depot")
Multiple options can be specified as list:
# Matches "Hospital", "*Depot" and all their subtypes
query = FS("site_facility_type.facility_type_id.name").typeof(["Hospital", "*Depot"])
In URLs, the operator is specified as __typeof like:
eden/org/facility?site_facility_type.facility_type_id.name__typeof=Hospital,*Depot
Where typeof is used with a virtual field, or no hierarchy is configured for the target table, it falls back to belongs (or anyof for list:types, respectively).
Attachments (1)
- hierarchy_data_model.png (15.1 KB ) - added by 11 years ago.
Download all attachments as: .zip

{kind=link}