
| Version 1 (modified by , 15 years ago) ( diff ) |
|---|
Table of Contents
S3XRC - S3Resource
Introduction
Resources are dynamic, document-alike representations of data objects on the Eden server. As such, they can represent both single instances as well as structured sets of data objects.
Note: in the database context, a single instance of a data object is typically called a record (or row), with fields (or columns) as its atomic elements. However, even though S3Resources are typically bound to a relational database and therefore the record/field terminology is often used in this regard, they are not intended to provide any object-relational mapping (ORM).
S3Resources implement an extensible, multi-format RESTful API to retrieve and manipulate data on the Eden server by HTTP requests, where every resource can be addressed by an individual URL.
In the context of the Model-View-Controller (MVC) architecture, S3Resources are controller-generated objects. Typically, the controller generates a resource in response to an incoming HTTP request and returns a view of it (output) to the client:

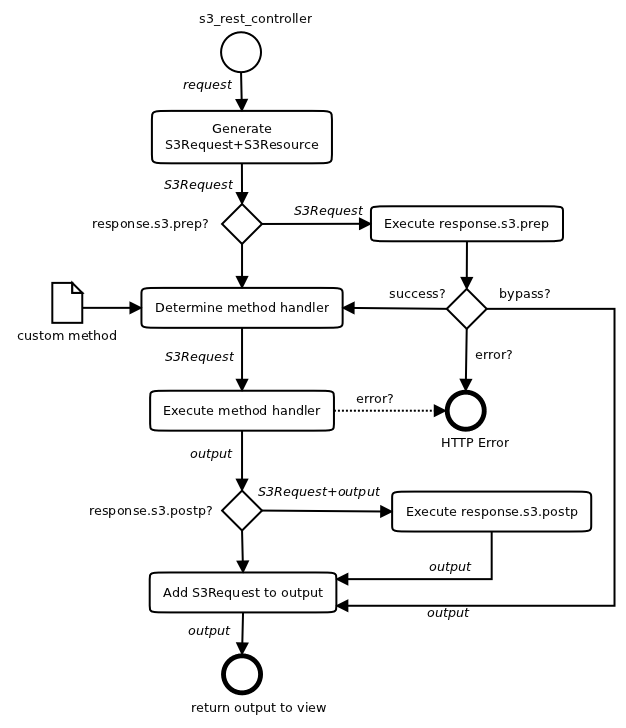
To parse the URL and the incoming HTTP request and to generate a corresponding resource, the controller can make use of the S3Request helper class.
Terminology
A S3Resource consists of elements which can be either resources themselves (container type) or data (atomic types).
Container type elements within a resource can be:
- primary resources (independent data objects)
- component resources (objects which are part of a primary object)
- referenced resources (objects which are referenced by primary or component resources)
REST Interface
This interface is used by the shn_rest_controller() function:
res, req = s3xrc.parse_request(module, resource, session, request, response) output = res.execute_request(req, **attr)
where res is the S3Resource, and req the S3Request.
Flow Diagram

Method Handlers
The default method handlers of shn_rest_controller() are implemented in models/01_crud.py:
- shn_read(r, attr)
- shn_list(r, attr)
- shn_create(r, attr)
- shn_update(r, attr)
- shn_delete(r, attr)
- shn_search(r, attr)
where r is the respective S3Request, and attr contains all further arguments passed to shn_rest_controller().
During the pre-process, you can re-configure which handlers shall be used by
r.resource.set_handler(action, handler)
where:
- action is the name of the action, i.e. one of 'read', 'list', 'create', 'update', 'delete', or 'search'
- handler is the handler function/lambda
Custom Methods
You can resource-specific custom methods by:
s3xrc.model.set_method(prefix, name, method, action)
where:
- prefix is the module prefix of a resource
- name is the name of the resource (without prefix)
- method is a string representing the name of the method (e.g. "search_simple")
- action is the method handler function/lambda
The action method has to take the same arguments as the default handlers: r (S3Request) and attr.
This features URLs like:
/prefix/name/<record_id>/<method>
Pre- and Post-Hooks
You can hook in a preprocessing function into the REST controller (as response.s3.prep) which will be called after the controller has parsed the request, but before it gets actually executed - with the current S3RESTRequest as argument (which includes the primary resource record, if any).
This allows you to easily make changes to resource settings (e.g. access control, list fields etc.), or even to the REST controller configuration (e.g. custom methods) depending on the request type, its parameters or the addressed resource, without having to parse the web2py request manually. You can even bypass the execution of the request and thus hook in your own REST controller - with the advantage that you don't need to parse the request anymore.
NB: Hooks should be added at the top of your controller function, especially pre-processing hooks.
A simple example:
Original code fragment:
if len(request.args) == 0:
# List View - reduce fields to declutter
table.message.readable = False
table.categories.readable = False
table.verified_details.readable = False
table.actioned_details.readable = False
response.s3.pagination = True #enable SSPag here!
return shn_rest_controller(module, resource, listadd=False)
Using the pre-processor hook instead:
def log_prep(jr):
if jr.representation == "html" and \
jr.method is None and \
jr.component is None:
# List View - reduce fields to declutter
table.message.readable = False
table.categories.readable = False
table.verified_details.readable = False
table.actioned_details.readable = False
return True
response.s3.prep = log_prep
response.s3.pagination = True #enable SSPag here!
return shn_rest_controller(module, resource, listadd=False)
The return value of the preprocessor function can simply be True, in which case the REST request will be executed as usual. Returning False would lead to a HTTP400 "Invalid Request" exception being raised.
The return value of the preprocessor function can also be a dict for more granular control - containing the following elements (all optional):
- success: boolean (default: True)
- output: dict (default: None)
- bypass: boolean (default: False)
If bypass is True, then the REST controller does not execute the request (the post-hook is executed, though). output must not be None in this case - it will be returned from the REST controller.
If success is False, and output is not None, then the REST controller does not execute the request, but just returns "output" (post-hook will not be executed in this case).
If success is False and output is None, a HTTP400 "Invalid Request" will be raised instead.
Examples:
In most cases, you will just return "True" - in some cases you might want to raise an error, e.g.:
response.error = "This request cannot be executed"
return dict(
success=False,
output=dict(title="My Pagetitle", item="Sorry, no data..."))
There is also a post-processing hook (response.s3.postp) that allows you to execute something directly after the REST request has been executed, but before the shn_rest_controller returns. The post-hook function will be called with the current S3RESTRequest and the output dict of its execution as arguments.
PostP Examples:
def user_postp(jr, output):
# Replace the ID column in List views with 'Action Buttons'
shn_action_buttons(jr)
return output
response.s3.postp = user_postp
def postp(r, output):
# Redirect to read/edit view after create rather than to list view
if r.representation == "html" and r.method == "create":
r.next = r.other(method="", record_id=s3xrc.get_session(session,
module, resource))
return output
response.s3.postp = postp
Passing information between main Controller & Prep
Scope normally means that these 2 sections can only talk to each other via globals or the Request object.
If you need to pass data between them, you can use this trick:
vars = {} # the surrounding dict
def prep(r, vars):
vars.update(x=y) # the actual variable to pass is x
return True
response.s3.prep = lambda r, vars=vars: prep(r, vars)
output = shn_rest_controller(module, resource)
x = vars.get(x, None)
An example usage is in controllers/gis.py for location()
Export behavior
The XML export function supports HTTP/GET. If no record ID is specified in the request, this will get a list attempt, otherwise a read attempt to the specified record. This is the same as for the Joined Resource Controller in general, except the following behaviour:
- when attempting to read a joined resource, you will get both the primary record and all belonging records in this joined resource.
- when attempting to read a primary resource, you will get both the primary record and all belonging records in all joined resources.
Import behavior
The XML import function supports HTTP/PUT, HTTP/POST as well as HTTP/GET with explicit create and update.
However, the use of POST is actually wrong here and is therefore handled like GET. The only way for list+create with ExtJS, though.
The behaviour is similar to the XML Export function:
- when there is no join in the request, resources will be joined automatically:
- the resource-element of the primary will be imported
- when joined resources for that element are also found in the XML source, they will be imported as well (all)
- when a joined resource is specified in the request, only elements for that joined resource will be imported - no other joined resources and not the primary record either
The import function can read from the request body (by default), but also pull from files or URL's:
- to import XML data from files, append a ?filename=<full_path_to_xml_file> variable to the request URL.
- to fetch XML data from URL's, append a ?fetchurl=<fully_qualified_url> variable to the request URL. Sources can be HTTP as well as FTP sources, as long as they export XML data.
This allows you to transfer resources directly from one Sahana Eden server to the other, e.g.:
http://localhost:8000/eden/pr/person/create?format=xml&fetchurl=http://vita.sahanafoundation.org/eden/pr/person.xml
fetches all person data (including all joined resources) from vita.sahanafoundation.org and creates or updates corresponding records on localhost.
Validation
Imported data is validated using the requires validators as specified in the models, before comitting them to the database.
In case of any validation error, no data import will happen at all. Instead, the import data tree with error attributes added to the erroneous elements (see JSON reponse format) will be returned.
To override this, you may specify "ignore_errors=True" in the URL. In this case the import just skips the erroneous records and always returns a success message (error messages are stored, but not returned). Note that "ignore_errors" is not recommended to be represented in regular a user interface, but just used manually if at all necessary (e.g. in manual pre-population of data).
Note: In contrast to validation errors, IntegrityError and IOError exceptions during data import do not prevent or roll back any data import that happened before the exception, and the returned element tree does not contain any error attributes, and these exceptions can not be overridden by "ignore_errors" either.
Onvalidation/Onaccept Callbacks
Import of records happens almost as if they were entered in HTML forms, i.e. onvalidation- and onaccept callbacks are executed as usual. They receive a pseudo-form as parameter, which is Storage() instead of Form(). Other than Form() objects, the pseudo-forms contain only form.vars (as usual, so most of the callbacks should work without change) and a form.method (which contains either "create" or "update") to indicate the action (which, in case of XML imports, can not be determined from the request).
NOTE: Never redirect from onvalidation or onaccept functions - this would break the XML import! Instead, set a flag in response.s3, and let the calling controller redirect upon this flag.
Authentication/Auditing
XML imports/exports are fully Auth-enabled, i.e. all actions are checked for permission and support auditing as specified in the Settings.
Response Format
The response object to create, update or delete requests in both XML as well as JSON representations always contains a JSON body like:
{
"status": "success", // "success" or "failed"
"statuscode": "200", // HTTP Status Code
"message" : "Ok", // Message as clear text (optional)
"tree" : { // Tree object in the JSON response indicates an error
// object containing the originally submitted data tree as described above
"$_my_resource": {
"myfield": {
"@value": "xxxx",
"$": "Bullshit",
"@error": "Validation Error: myfield must be integer!" // @error indicates an error for this field
}
}
}
}
- tree is only returned in case of an error during Create or Update actions
- @error attributes can be re-sent (will be removed by the controller)
UUID Mapping and Matching
On data export, all references are mapped from internal id's to uuid's - given that uuid's are present in the referenced table, otherwise the reference field is not represented in XML or JSON at all.
On data import, all references are mapped back from uuid's to internal id's, provided that the referenced record (with that uuid) exists in the database, otherwise the reference field is not imported (get's a default value).
On data import with create method, records with matching UUID's will automatically get updated instead of newly created.
Therefore, for resources that have to be exchanged, the use of UUID's is highly recommended.
In-line transformation with XSLT

The XML/JSON interface uses XSLT to transform data from/to the raw XML/JSON format into foreign formats.
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output method="xml"/>
<xsl:template match="/">
<xsl:copy-of select="."/>
</xsl:template>
</xsl:stylesheet>
This is just an example template for import/export, but it is not used. Instead, when you specify the native formats "xml" or "json", the raw formats described above are used.
To enable other formats, you have to:
For import:
- put an XSLT template for import into static/xsl/import and name the template <format>.xslt (e.g. pfif.xslt)
- in the file models/01_crud.py add the <format> name to this line:
shn_xml_import_formats = ["xml", "pfif"]
For export analogous:
- put an XSLT template for export into static/xsl/export and name the template <format>.xslt (e.g. pfif.xslt)
- in the file models/01_crud.py add the <format> name to this line:
shn_xml_export_formats = ["xml", "pfif"]
From there, you can use that format name as either extension or ?format= option in requests:
Export:
http://localhost:8000/eden/pr/person/1.pfif
Import:
http://localhost:8000/eden/pr/person/1.pfif/create
and the corresponding XSL template will now be used at import/export from/into that format.
Note: "json" and "xml" must be in the format lists in models/01_crud.py!
- EditiX - free GUI XSLT debugger (Java-based, so x-platform)
- Xalan - free CLI XSLT debugger (Java-based, so x-platform)
- Docs: DeveloperGuidelinesTips
Attachments (2)
- arch3.png (8.0 KB ) - added by 15 years ago.
- s3rest.png (43.4 KB ) - added by 14 years ago.
Download all attachments as: .zip

{kind=link}
{kind=link}